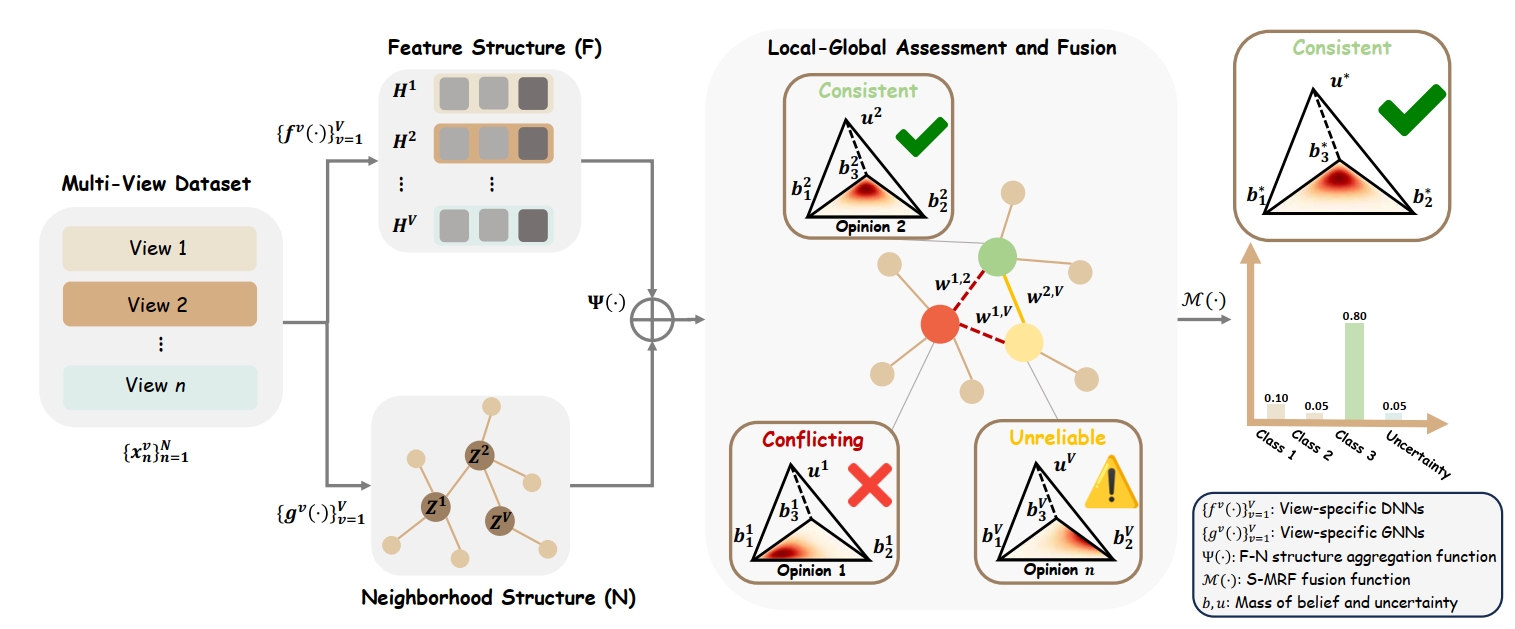
@article{huang2024trusted,title={Trusted Unified Feature-Neighborhood Dynamics for Multi-View Classification},author={Huang, Haojian and Qin, Chuanyu and Liu, Zhe and Ma, Kaijing and Chen, Jin and Fang, Han and Ban, Chao and Sun, Hao and He, Zhongjiang},journal={AAAI},booktitle={Association for the Advancement of Artificial Intelligence Conference},year={2025},}
2024
arXiv
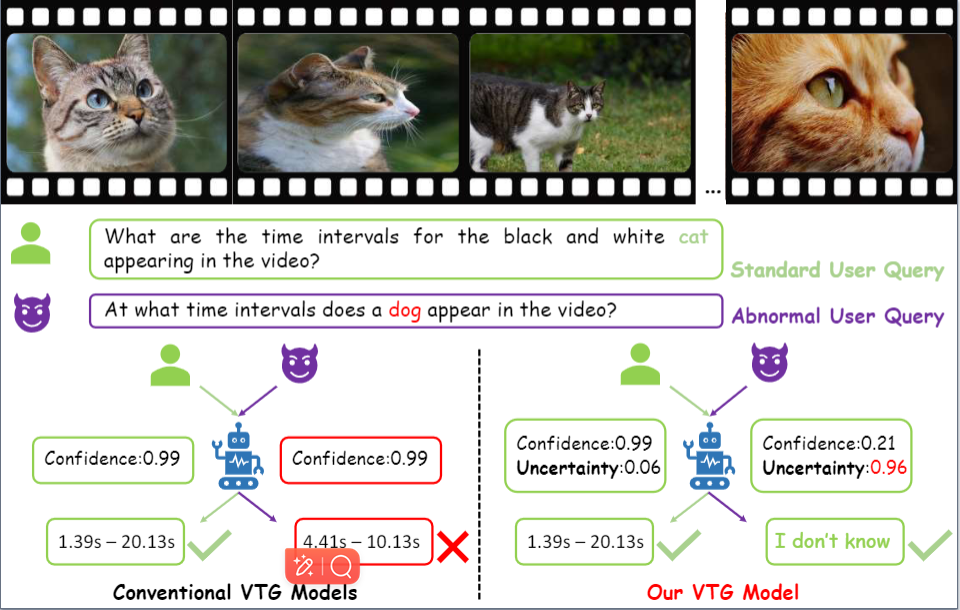
Beyond Uncertainty: Evidential Deep Learning for Robust Video Temporal Grounding
Kaijing Ma*, Haojian Huang*, Jin Chen*, Haodong Chen, Pengliang Ji, Xianghao Zang, Han Fang, Chao Ban, Hao Sun, Mulin Chen, and others
@article{ma2024beyond,title={Beyond Uncertainty: Evidential Deep Learning for Robust Video Temporal Grounding},author={Ma, Kaijing and Huang, Haojian and Chen, Jin and Chen, Haodong and Ji, Pengliang and Zang, Xianghao and Fang, Han and Ban, Chao and Sun, Hao and Chen, Mulin and others},journal={arXiv preprint arXiv:2408.16272},year={2024},booktitle={arXiv preprint},}
ACM MM
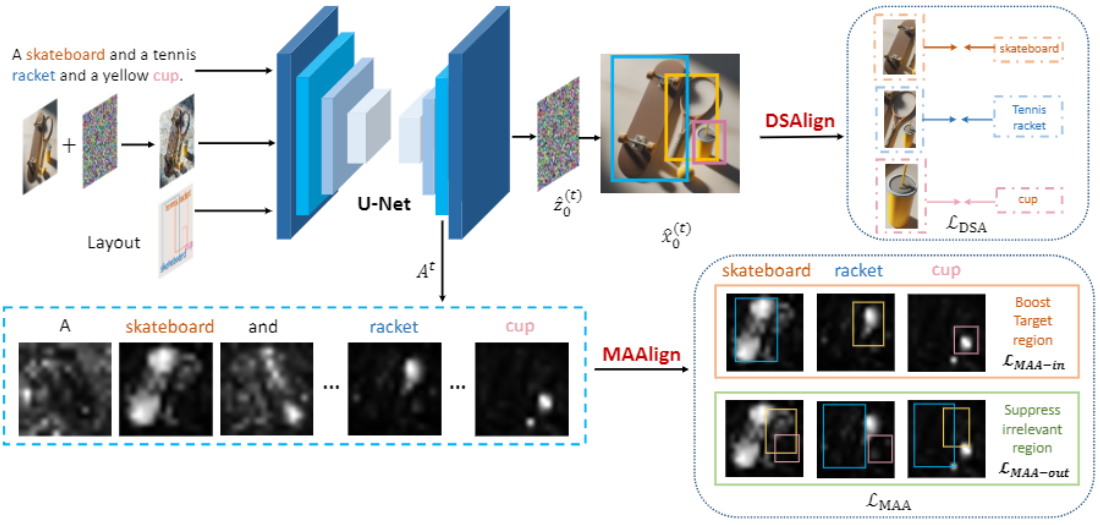
GOAL: Grounded text-to-image Synthesis with Joint Layout Alignment Tuning
@inproceedings{li2024goal,title={GOAL: Grounded text-to-image Synthesis with Joint Layout Alignment Tuning},author={Li, Yaqi and Fang, Han and Feng, Zerun and Ma, Kaijing and Ban, Chao and Zang, Xianghao and Zhou, LanXiang and He, Zhongjiang and Chen, Jingyan and Hu, Jiani and others},booktitle={ACM Multimedia 2024},year={2024},}
arXiv
BoViLA: Bootstrapping Video-Language Alignment via LLM-Based Self-Questioning and Answering
Jin Chen, Kaijing Ma, Haojian Huang, Jiayu Shen, Han Fang, Xianghao Zang, Chao Ban, Zhongjiang He, Hao Sun, and Yanmei Kang
@article{chen2024bovila,title={BoViLA: Bootstrapping Video-Language Alignment via LLM-Based Self-Questioning and Answering},author={Chen, Jin and Ma, Kaijing and Huang, Haojian and Shen, Jiayu and Fang, Han and Zang, Xianghao and Ban, Chao and He, Zhongjiang and Sun, Hao and Kang, Yanmei},journal={arXiv preprint arXiv:2410.02768},booktitle={arXiv preprint},year={2024}}
2023
ICCVW
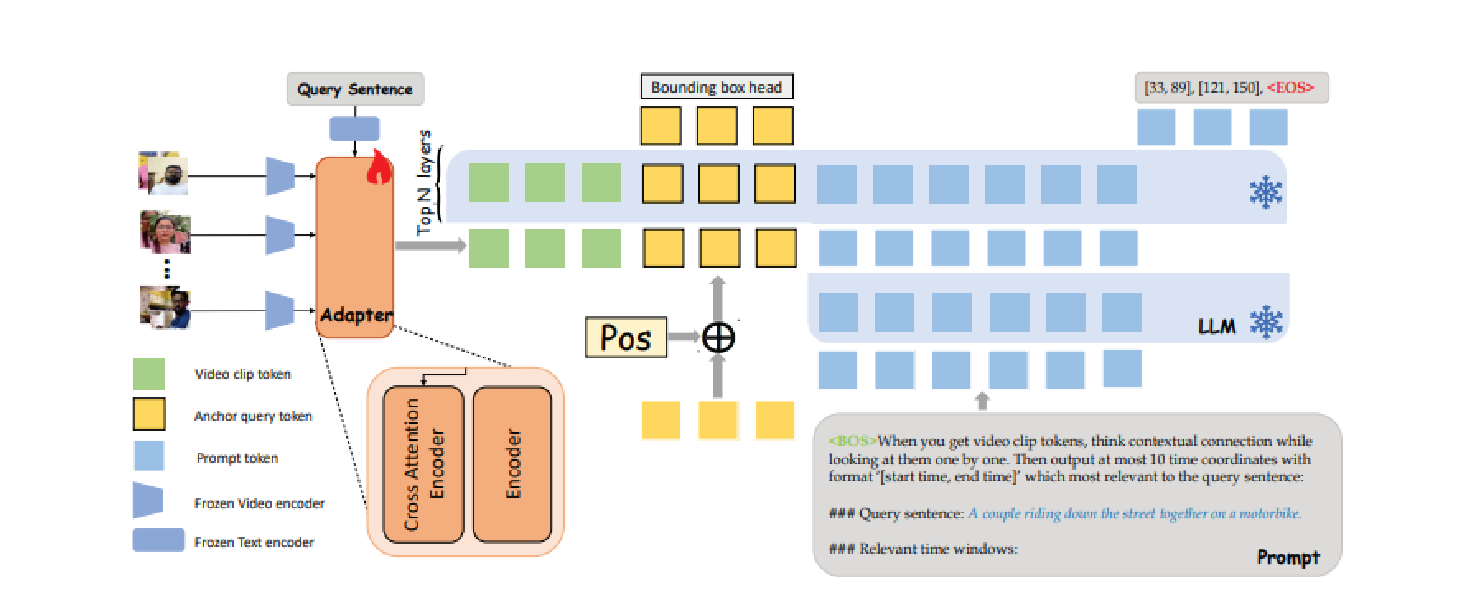
LLaViLo: Boosting Video Moment Retrieval via Adapter-Based Multimodal Modeling
Kaijing Ma*, Xianghao Zang*, Zerun Feng, Han Fang, Chao Ban, Yuhan Wei, Zhongjiang He, Yongxiang Li, and Hao Sun†
In Proceedings of the IEEE/CVF International Conference on Computer Vision, 2023
@inproceedings{ma2023llavilo,title={LLaViLo: Boosting Video Moment Retrieval via Adapter-Based Multimodal Modeling},author={Ma, Kaijing and Zang, Xianghao and Feng, Zerun and Fang, Han and Ban, Chao and Wei, Yuhan and He, Zhongjiang and Li, Yongxiang and Sun, Hao},booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision},pages={2798--2803},year={2023},}