Kaijing Ma
Internship @Shanghai AI Lab  ,
,
Master student @XJTU  & @TeleAI
& @TeleAI  ,
,
Incoming PhD Student @FDU
“The future is already here – it’s just not evenly distributed.”
Hi there! ☺️
My name is Kaijing. Currently, I am interning at Embodied AI Center@Shanghai AI Laboratory, working with Prof.Tong He. We are a young team focusing on Robotics. I have a strong belief in developing Foundation Embodied AI Models with zero-shot cross-embodiment capabilities.
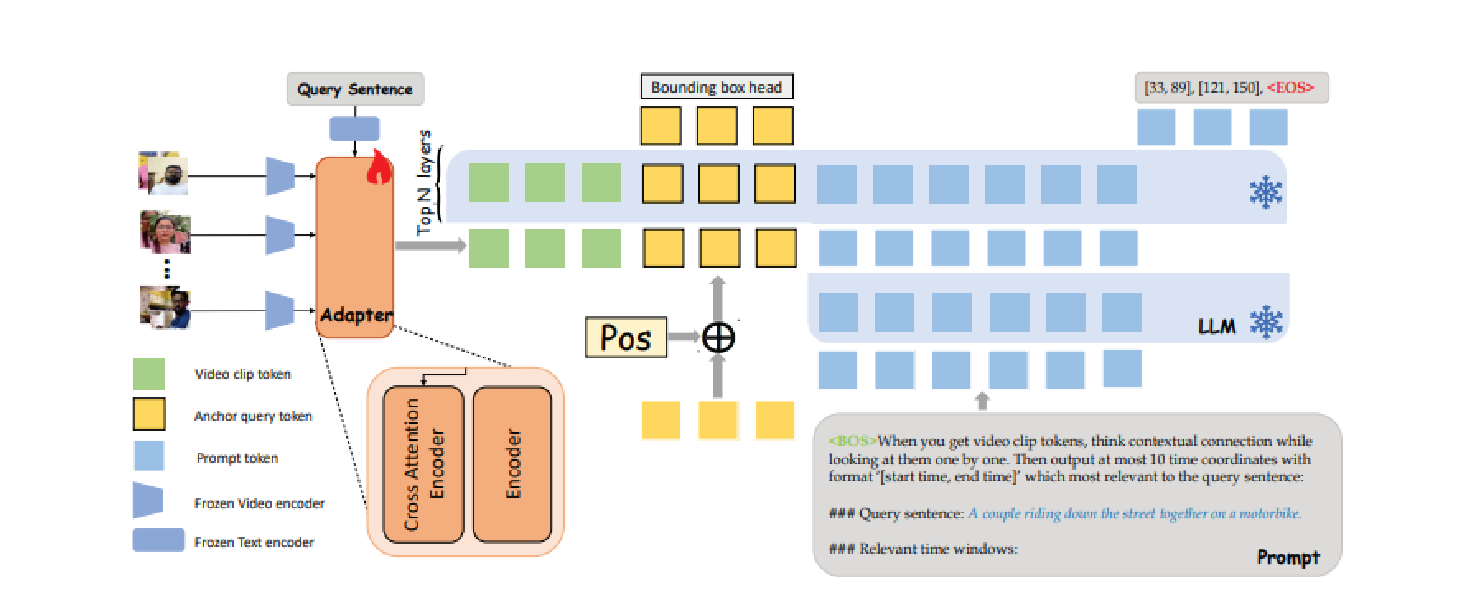
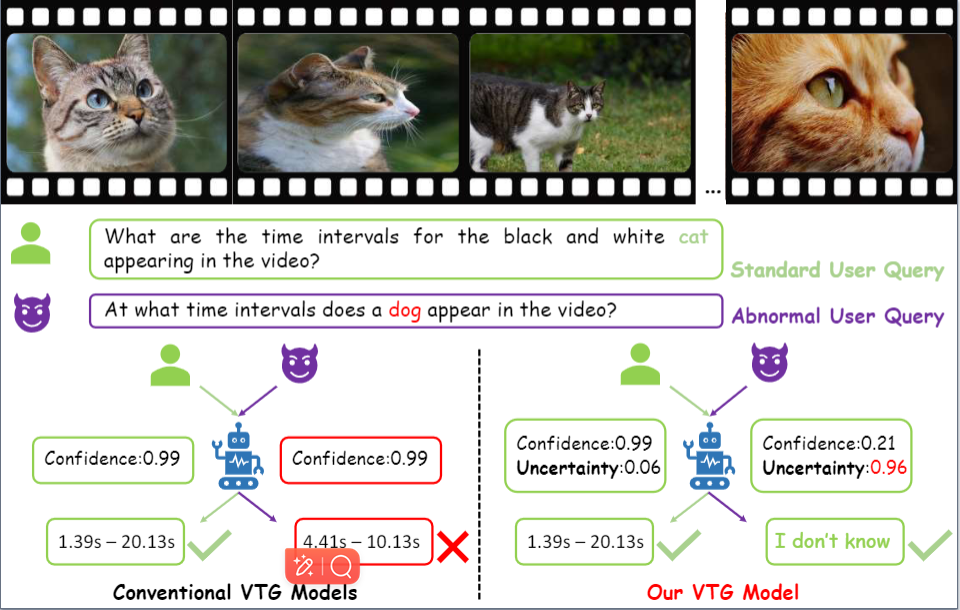
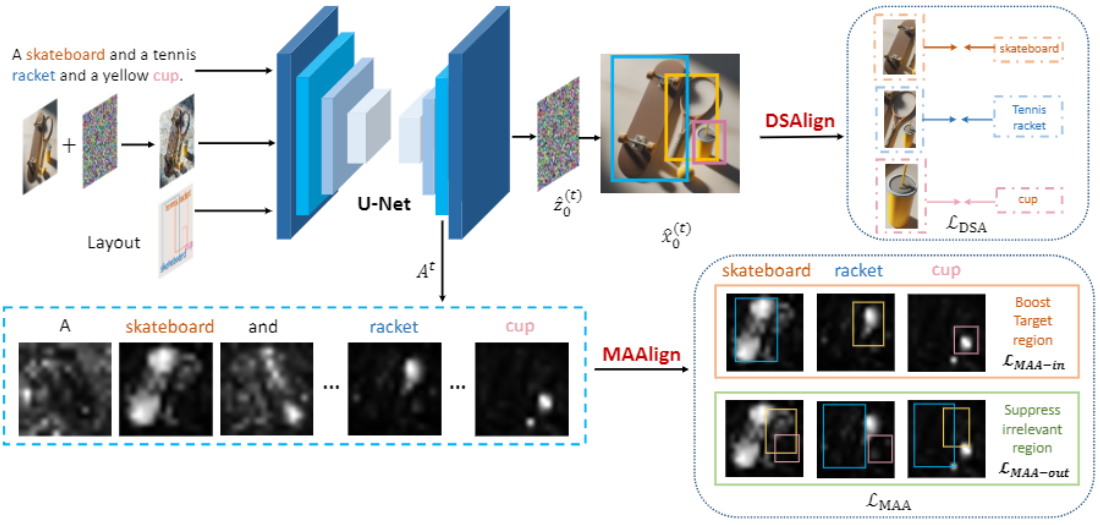
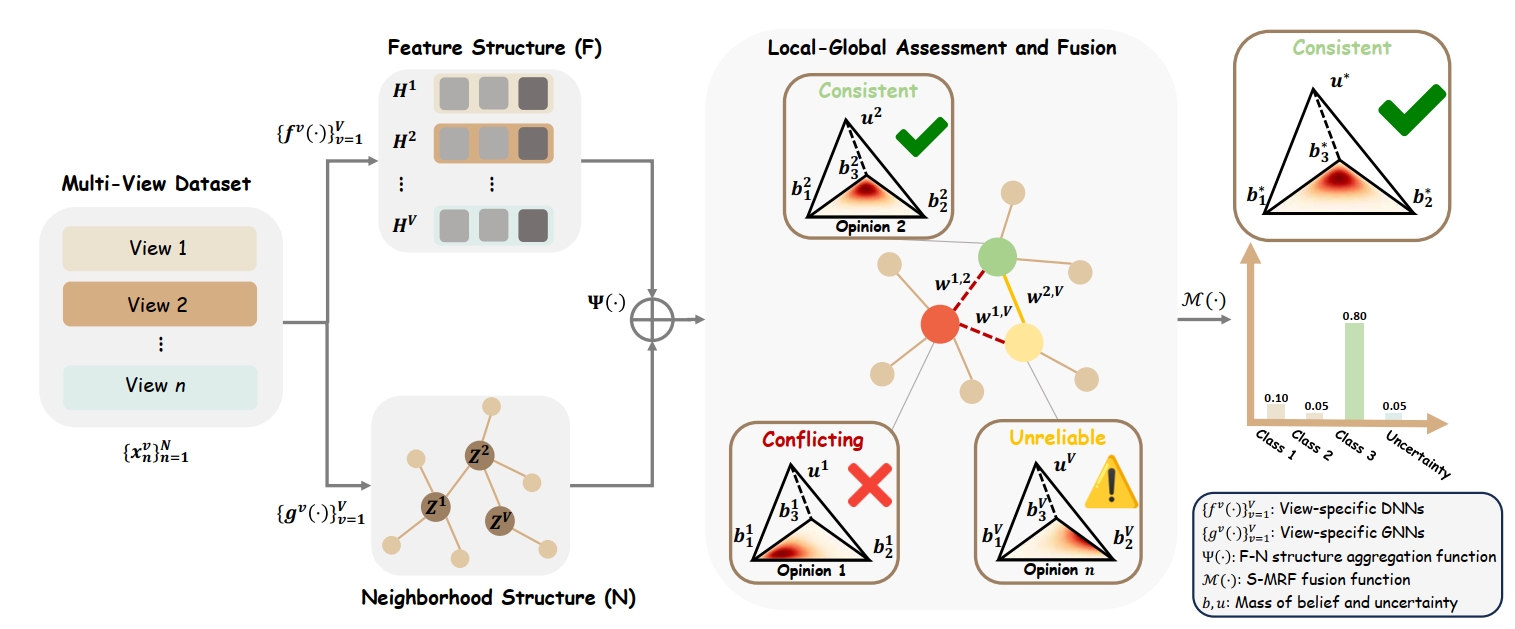
Back in 2022, I was enrolled in a Masters Industry Co-Op Education Program between Xi’an Jiaotong University and TeleAI. At TeleAI, I focus on building state-of-the-art multimodal understanding and generation models, such as Video Temporal Grounding and controllable text-to-image models. For example, we have launched TeleImage (aka: 星辰多模态大模型), an advanced text-to-image generation product for the public. Our team is led by Prof.Xuelong Li, who is also the CTO and Chief Scientist of China Telecom.
News
| Dec 10, 2024 | Our paper TUNED has been accepted by AAAI-25🙂. Feel free to access the paper and code . |
|---|---|
| Sep 21, 2024 | Received the ‘Excellence in Engineering Award (Student Category)’ from the National School for Engineers at Xi’an Jiaotong University🥳 |
| Sep 14, 2024 | We released the code of SRAM🔥 |
| Jul 15, 2024 | Our Paper About Controllable Text-to-image Generation has been accepted by ACM MM2024! |
| Mar 15, 2024 | Our paper about moment retrieval has been accepted as oral paper by ICME 2024. |
| Jul 15, 2023 | Our paper about moment retrieval hsa been accepted by ICCV Workshop 2023. |